How to Avoid Fighting Rust Borrow Checker
The 3 important facts in Rust:
- Tree-shaped ownership. In Rust's ownership system, one object can own many children or no child, but must be owned by exactly one parent. Ownership relations form a tree. 1
- Mutable borrow exclusiveness. If there exists one mutable borrow for an object, then no other borrow to that object can exist. Mutable borrow is exclusive.
- Borrow is contagious. If you borrow a child, you indirectly borrow the parent (and parent's parent, and so on). Mutably borrowing one wheel of a car makes you borrow the whole car, preventing another wheel from being borrowed. It can be avoided by split borrow which only works within one scope.
Considering reference shape
Firstly consider the reference 2 shape of your in-memory data.
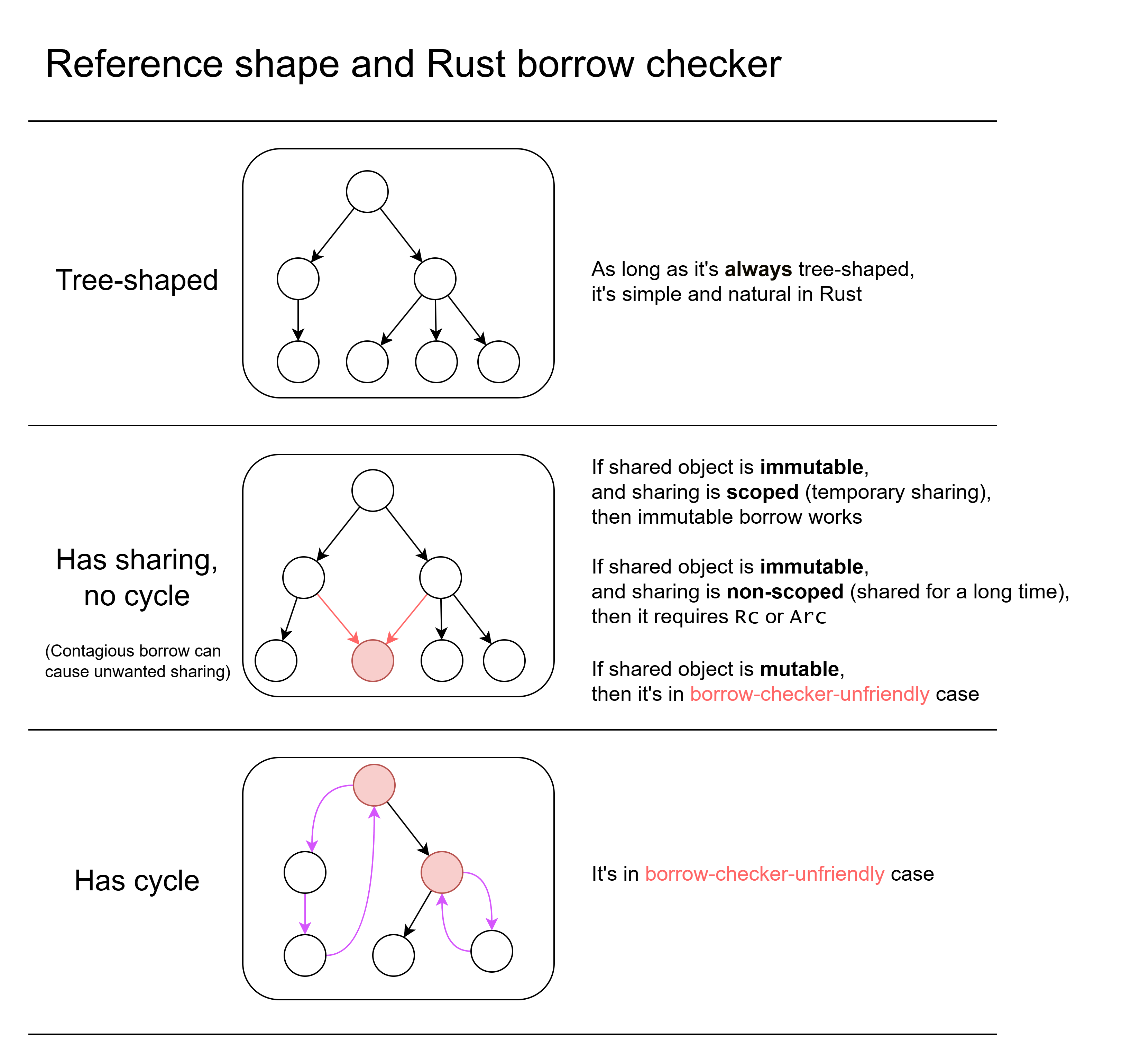
- If the reference is tree-shaped, then it's simple and natural in Rust.
- If the reference shape has sharing, things become a little complicated.
- Sharing means there are two or more references to the same object.
- If shared object is immutable:
- If the sharing is scoped (only temporarily shared), then you can use immutable borrow. You may need lifetime annotation.
- If the sharing is not scoped (may share for a long time, not bounded within a scope), you need to use reference counting (
Rcin singlethreaded case,Arcin possibly-multithreaded case)
- If shared object is mutable, then it's in borrow-check-unfriendly case. Solutions elaborated below.
- Contagious borrow can cause unwanted sharing (elaborated below).
- If the reference shape has cycle, then it's also in borrow-check-unfriendly case. Solutions elaborated below.
The most fighting with borrow checker happens in the borrow-check-unfriendly cases.
Summarize solutions
The solutions in borrow-checker-unfriendly cases (will elaborate below):
- Data-oriented design. (less OOP)
- Avoid unnecessary getter and setter.
- Use ID/handle to replace borrow. Use arena to hold data.
- No need to put one object's all data into one struct. Can separate to different places.
- Do split borrow in outer scope, and pass related fields separately.
- Defer mutation. Turn mutation as commands and execute later.
- Avoid in-place mutation. Mutate-by-recreate. Use
Arcto share immutable data. Use persistent data structure. - For circular reference:
- For graph data structure, use ID/handle and arena.
- For callbacks, replace capturing with arguments, or use event handling to replace callback.
- Borrow as temporary as possible. For example, replace container for-loop
for x in &vec {}with raw index loop. - Refactor data structure to avoid contagious borrow.
- Reference counting and interior mutability.
Arc<QCell<T>>,Arc<RwLock<T>>, etc. (only use when really necessary) unsafeand raw pointer (only use when really necessary)
Contagious borrow issue
Contagious borrow issue is a very common and important source of frustrations in Rust, especially for beginners.
The previously mentioned two important facts:
- Mutable borrow exclusiveness. If you mutably borrow one object, others cannot borrow it.
- Borrow is contagious. If you borrow a child, you indirectly borrow the parent (and parent's parent, and so on), which contagiously borrow other childs of the same parent. Mutably borrowing one wheel of a car makes you borrow the whole car, including all 4 wheels, then the wheel that you don't use cannot be borrowed. This don't happen under split borrow.
A simple example:
pub struct Parent {
total_score: u32,
children: Vec<Child>
}
pub struct Child {
score: u32
}
impl Parent {
fn get_children(&self) -> &Vec<Child> {
&self.children
}
fn add_score(&mut self, score: u32) {
self.total_score += score;
}
}
fn main() {
let mut parent = Parent{total_score: 0, children: vec![Child{score: 2}]};
for child in parent.get_children() {
parent.add_score(child.score);
}
}
Compile error:
25 | for child in parent.get_children() {
| ---------------------
| |
| immutable borrow occurs here
| immutable borrow later used here
26 | parent.add_score(child.score);
| ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ mutable borrow occurs here
(That simplified example is just for illustrating contagious borrow issue. The total_score is analogous to a complex state that exists in real applications. Same for subsequent examples. Just summing integers can be done by .sum() or local variable. Simple integer mutable state can be workarounded using Cell.)
That code is totally memory-safe: the .add_score() only touch the total_score field, and .get_children() only touch the children field. They work on separate data, but borrow checker thinks they overlap, because of contagious borrow:
- In
fn get_children(&self) -> &Vec<Child> { &self.children }, although the method body just borrowschildrenfield, the return value indirectly borrows the wholeself, not just one field. - In
fn add_score(&mut self, score: u32) { self.total_score += score; }, the function body only mutably borrowedtotal_scorefield, but the argument&mut selfborrows the wholeParent, not just one field. - Inside the loop, one immutable borrow to the whole
Parentand one mutable borrow to the wholeParentoverlaps in lifetime.
You just want to borrow one field, but forced to borrow the whole object.
What if I just inline get_children and add_score? Then it compiles fine:
pub struct Parent {
total_score: u32,
children: Vec<Child>
}
pub struct Child {
score: u32
}
fn main() {
let mut parent = Parent{total_score: 0, children: vec![Child{score: 2}]};
for child in &parent.children {
let score = child.score;
parent.total_score += score;
}
}
Why that compiles? Because it does a split borrow: the compiler sees borrowing of individual fields in one function (main()), and don't do contagious borrow.
The deeper cause is that:
-
Borrow checker works locally: when seeing a function call, it only checks function signature, instead of checking code inside the function.
The borrow checker works locally because:
- If it checks method body, it need to do whole-program analysis. It's complex and slow.
- It improves decoupling. You don't need to worry a library's changing of function body makes your code stop compling. That decoupling is also required by dynamic linking.
-
Information is lost in function signature: the borrowing information becomes coarse-grained and is simplified in function signature. The type system does not allow expressing borrowing only one field, and can only express borrowing the whole object.
Summarize solutions (workarounds) of contagious borrow issue (elaborated below):
- Remove unnecessary getters and setters.
- Just simply make fields public (or in-crate public). This enables split borrow in outer code. If you want encapsulation, use ID/handle to replace borrow of mutable data (elaborated below).
- The getter that returns cloned/copied value is fine.
- If data is immutable, getter is also fine.
- Reorganize code and data structure. 3
- Defer mutation
- Avoid in-place mutation
- Do a split borrow on the outer scope. Or just get rid of struct, pass fields as separate arguments. (This is inconvenient.)
- Manually manage index (or key) in container for-loop. Borrow as temporary as possible.
- Just clone the data (can be shallow-clone).
- Use the borrow crate. After borrowing one field the remaining fields' borrowing are put into another value in new type, using "macro magic". 4
- Use interior mutability (cells and locks).
There are proposed language design solutions to contagious borrow issue: 5
- Encode field-level borrow information in type. Vew type. It doen't work well with encapsulation (internal field info is leaked into type). And handling private fields while keeping API compatibility is hard. Tracking issue.
- Do implicit field-level borrow analysis in private functions. Avoid exposing partial borrow in public API. It avoids API compatibility issue. It makes borrow checking inter-function (not just check function signature). Automatic partial borrows for private methods.
Inlining can allow split borrow. But inling can cause code to become messy. A workaround is to use closures. Closures in local scope can work with split borrow:
let mut parent = Parent{total_score: 0, children: vec![Child{score: 2}]};
let get_children = || parent.children;
let mut add_score = |score: u32| parent.total_score += score;
for child in get_children() {
add_score(child.score);
}
Defer mutation. Mutation-as-data
Another solution is to treat mutation as data. To mutate something, append a mutation command into command queue. Then execute the mutation commands at once. (Note that command should not indirectly borrow base data.)
- In the process of creating new commands, it only do immutable borrow to base data, and only one mutable borrow to the command queue at a time.
- When executing the commands, it only do one mutable borrow to base data, and one borrow to command queue at a time.
What if I need the latest state before executing the commands in queue? Then inspect both the command queue and base data to get latest state (LSM tree does similar things). You can often avoid needing to getting latest state during processing, by separating it into multiple stages.
The previous code rewritten using deferred mutation:
pub struct Parent {
total_score: u32,
children: Vec<Child>
}
pub struct Child {
score: u32
}
pub enum Command {
AddTotalScore(u32),
// can add more kinds of commands
}
impl Parent {
fn get_children(&self) -> &Vec<Child> {
&self.children
}
fn add_score(&mut self, score: u32) {
self.total_score += score;
}
}
fn main() {
let mut parent = Parent{total_score: 0, children: vec![Child{score: 2}]};
let mut commands: Vec<Command> = Vec::new();
for child in parent.get_children() {
commands.push(Command::AddTotalScore(child.score));
}
for command in commands {
match command {
Command::AddTotalScore(num) => {
parent.add_score(num);
}
};
}
}
Deferred mutation is not "just a workaround for borrow checker". Treating mutation as data also has other benefits:
- The mutation can be serialized, and sent via network or saved to disk.
- The mutation can be inspected for debugging and logging.
- You can post-process the command list, such as sorting, filtering.
- Easier parallelism. The process of generating mutation command does not mutate the base data, so it can be parallelized. If data is sharded, the execution of mutation commands can be dispatched to shards executing in parallel.
Other applications of the idea of mutation-as-data:
- Transactional databases often use write-ahead log (WAL) to help atomicity of transactions. Database writs all mutations into WAL. Then after some time the mutations in WAL will be merged to base data in disk.
- Event sourcing. Derive the latest state from events and previous checkpoint. Distributes systems often use consensus protocol (like Raft) to replicate log (events, mutations). The mutable data is derived from logs and previous checkpoint.
- The idea of turning operations into data is also adopted by io_uring and modern graphics APIs (Vulkan, Metal, WebGPU).
- In ClickHouse, mutation can be achieved by insertion-and-aggregation (e.g. addition becomes sum aggregation, overwriting becomes max-by-timestamp aggregation). 6
- In modern CPUs, writing to memory is often putting data to store buffer. The actual memory write is delayed and batched.
Avoid in-place mutation
The previous problem can be avoided if you don't do in-place mutation.
One ways is mutate-by-recreate: The data is immutable. When you want to mutate something, you create a new version of it. It's widely used in functional programming.
Sometimes transforming is better than mutating. Instead of mutating in-place, consume old state and compute new state.
The old state can use different type than new state, which can improve type safety (Typestate pattern). For example, if it has an Option<T> field that need to be filled in a function, separate input and output as two types, the input type don't have that field, the output has that field of type T (not Option<T>). This can avoid .unwrap(). (Its downside is that you may duplicate some fields and have more types.)
Not doing in-place mutation can reduce chance of bugs. In OOP languages it's easy to wrongly share mutable object. Mutating a wrongly-shared object may cause bugs. Rust helps reducing these bugs.
Mutate-by-recreate is contagious up to parent: if you recreated a new version of a child, you need to also recreate a new version of parent that holds the new child, and parent's parent, and so on, until a "mutable root". There are abstractions like lens to make this kind of cascade-recreate more convenient.
Mutate-by-recreate can be useful for cases like:
- Safely sharing data in multithreading (read-copy-update (RCU), copy-on-write (COW)). Only make one "root reference" be mutable atomically. Mutating is recreating whole object. (It's often used with arc_swap)
- Take snapshot and rollback efficiently
Persistent data structure: they share unchanged sub-structure (structural sharing) to make mutate-by-recreate faster. Some crates of persistent data structures: rpds, im, pvec.
Example of mutating hash map while looping on a clone of it, using rpds:
let mut map: HashTrieMap<i32, i32> = HashTrieMap::new();
map = map.insert(2, 3);
for (k, v) in &map.clone() {
if *v > 2 {
map = map.insert(*k * 2, *v / 2);
}
}
Split borrow
As previously mentioned, if you separately borrow two fields of a struct within one scope (e.g. a function), Rust will do a split borrow. This can solve contagious borrow issue. Getter and setter functions break split borrow, because borrowing information become coarse-grained in function signature.
Contagious borrow can also happen in containers. If you borrow one element of a container, then another element cannot be mutably borrowed. How to split borrow a container:
- For
Vecand slice, usesplit_at_mut - For
HashMap, useget_disjoint_mut - For
BTreeMap, the standard library doesn't provide a way. 7
Avoid iterator. Manually manage index (key) in loop
For looping on container is very common. However, the common container for loop (e.g. for x in &container {...}) has an implicit iterator that keeps borrowing the whole container.
One solution is to manually manage index (key) in loop, without using iterator. For Vec or slice, you can make index a mutable local variable, then use while loop to traverse the array.
The previous example rewritten using manual loop:
pub struct Parent {
total_score: u32,
children: Vec<Child>
}
pub struct Child { score: u32 }
impl Parent {
fn get_children(&self) -> &Vec<Child> { &self.children }
fn add_score(&mut self, score: u32) { self.total_score += score; }
}
fn main() {
let mut parent = Parent{total_score: 0, children: vec![Child{score: 2}]};
let mut i: usize = 0;
while i < parent.get_children().len() {
let score = parent.get_children()[i].score;
parent.add_score(score);
i += 1;
}
}
It calls .get_children() many times. Each time, the result borrow is kept for only a short time. After copying the score field of element, it stops borrowing the element, which then indirectly stops borrowing the parent.
Note that it requires stop borrowing the element before doing mutation. That example copies score integer so it can stop borrowing the child. For non-Copy-able data, you need cloning to stop borrowing element (reference counting and persistent data structure can avoid deep cloning).
(Rust doesn't have C-style for loop for (int i = 0; i < len; i++).)
The similar thing can be done in BTreeMap. We can get the minimum key, then iteratively get next key. This allows looping on BTreeMap without keeping borrowing it.
Example of mutating a BTreeMap when looping on it.
let mut map: BTreeMap<i32, i32> = BTreeMap::new();
map.insert(2, 3);
let mut curr_key_opt: Option<i32> = map.first_key_value().map(|(k, _v)| *k);
while let Some(current_key) = curr_key_opt {
let v: &i32 = map.get(¤t_key).unwrap();
if *v > 2 {
map.insert(current_key * 2, *v / 2);
}
curr_key_opt = map.range((Bound::Excluded(¤t_key), Bound::Unbounded))
.next().map(|(k, _v)| *k);
}
Note that it requires copying/cloning the key, and stop borrowing element before mutating.
That way doesn't work for HashMap. HashMap doesn't preserver order and doesn't allow getting the next key. But that way can work on indexmap's IndexMap, which allows getting key by integer index (it internally uses array, so removing or adding in the middle is not fast).
Just (shallow) clone the data
Cloning data can avoid keeping borrowing the data. For immutable data, wrapping in Rc (Arc) then clone can work:
The previous example rewritten by wrapping container in Rc then for-loop:
pub struct Parent { total_score: u32, children: Rc<Vec<Child>> }
pub struct Child { score: u32 }
impl Parent {
fn get_children(&self) -> Rc<Vec<Child>> {
self.children.clone() // Note: clones
}
fn add_score(&mut self, score: u32) {
self.total_score += score;
}
}
fn main() {
let mut parent = Parent{total_score: 0, children: Rc::new(vec![Child{score: 2}])};
for child in parent.get_children().iter() {
parent.add_score(child.score);
}
}
For mutable data, to make cloning and mutation more efficient, the previously mentioned persistent data structure can be used.
If the data is small, deep cloning is usually fine. If it's not in hot code, deep cloning is also usually fine.
For container contagious borrow, a solution is to firstly copy the keys to a new container then use keys to access the container.
There is a misconception: "I already choosed Rust. So I must optimize performance to justify 'Rust cost'. I must not do any unnecessary copy." The performance follows 80/20 rule. 80% of time is spent executing 20% code 8. If some code is not bottleneck, optimizing it has neglegible effect. Only optimize after knowing bottleneck.
Workaround by swapping container (not recommended)
Another workaround is to temporarily swap the container to another place. Then it can loop on container without borrowing parent object. When it finishes, it swaps back.
pub struct Parent { total_score: u32, children: Vec<Child> }
pub struct Child { score: u32 }
impl Parent {
fn get_children_mut(&mut self) -> &mut Vec<Child> { &mut self.children }
fn add_score(&mut self, score: u32) { self.total_score += score; }
}
fn main() {
let mut parent = Parent{total_score: 0, children: vec![Child{score: 2}]};
let mut temp_children: Vec<Child> = Vec::new();
mem::swap(&mut temp_children, parent.get_children_mut());
for child in &temp_children {
parent.add_score(child.score);
}
mem::swap(&mut temp_children, parent.get_children_mut());
}
It swaps the continer's internal pointer. It doesn't copy container content, so its performance cost is small.
But it's error-prone. It requires not forgetting to swap back. It also requires recovering druing panic unwind. Also if some logic nests, the inner logic will see wrong empty container. Generally not recommended.
Related: sometimes you want to avoid deep copying content, but you cannot take ownership, then one solution is to mem::replace it with an empty container. This is a normal pattern, different to the temporary swap.
Contagious borrowing between branches
It's a common pattern that we cache some things using a map. If the element is not in cache, we compute it and put into map.
We want the borrow the value in cache to avoid cloning the value:
fn get_cached_result(cache: &mut HashMap<i32, String>, key: i32) -> &String {
match cache.get(&key) {
None => {
let computed_value = "result of computation".to_string();
cache.insert(key, computed_value);
cache.get(&key).unwrap() // value is moved into map so get again
}
Some(v) => {v}
}
}
It triggers contagious borrow between branches:
error[E0502]: cannot borrow `*cache` as mutable because it is also borrowed as immutable
--> src\main.rs:9:13
|
5 | fn get_cached_result(cache: &mut HashMap<i32, String>, key: i32) -> &String {
| - let's call the lifetime of this reference `'1`
6 | match cache.get(&key) {
| ----- immutable borrow occurs here
...
9 | cache.insert(key, computed_value);
| ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ mutable borrow occurs here
...
12 | Some(v) => {v}
| - returning this value requires that `*cache` is borrowed for `'1`
In Rust, expressions can output a value. In that case the match expression outputs a value. That match has two branches. Each branch also output a value.
Because the match target cache.get(&key) indirectly borrows cache mutably. And the second branch Some(v) => {v}'s output indirectly borrow match target. This indirect borrow of cache is contagious to the whole match expression. In cache.insert it also mutably borrows cache so it conflicts.
One workaround: firstly use containes_key to check whether should insert. After that, read from the map again:
fn get_cached_result(cache: &mut HashMap<i32, String>, key: i32) -> &String {
if !cache.contains_key(&key) {
let computed_value = "result of computation".to_string();
cache.insert(key, computed_value);
}
cache.get(&key).unwrap()
}
The contains_key gives a bool that doesn't borrow anything. The branch also has no output value now.
That solution is not elegant because both contains_key and get lookups the map. If cache hits it lookups twice but it actually only need once. (The extra cost may can be optimized out by compiler).
A more elegant solution is to use entry API:
fn get_cached_result(cache: &mut HashMap<i32, String>, key: i32) -> &String {
cache.entry(key).or_insert_with(|| {
"result of computation".to_string()
})
}
(The entry API was specifically designed to workaround this borrow checker limitation.)
Another workaround is to wrap map value in Arc (or Rc) then clone the Arc when accessing.
This will be fixed by Polonius borrow checker. Currently (2025 Aug) it's available in nightly Rust and can be enabled by an option. See also
That issue can also be workarounded by cloning value in map.
Callbacks
Callbacks are commonly used in GUIs, games and other dynamic reactive systems. If parent want to be notified when some event happens on child, the parent register callback to child, and child calls callback when event happens.
However, the callback function object often have to reference the parent (because it need to use parent's data). Then it creates circular reference: parent references child, child references callback, callback references parent. This creates trouble as Rust is unfriendly to circular reference.
Summarize solutions to circular reference callbacks:
- Replace capturing with argument.. Don't make the callback capture parent borrow. Pass parent borrow in argument. This can break the circular reference.
- Turn events into data. Use ID/handle to refer to objects. Don't use callback. Just create events and process events.
- (Not recommended) Use reference counting and interior mutability, like
Rc<RefCell<>>.
For example, in a GUI application, I have a counter and a button, clicking button increments counter:
struct ParentComponent {
button: ChildButton,
counter: u32,
}
struct ChildButton {
on_click: Option<Box<dyn FnMut() -> ()>>,
}
fn main() {
let mut parent = ParentComponent {
button: ChildButton { on_click: None },
counter: 0
};
parent.button.on_click = Some(Box::new(|| {
parent.counter += 1;
}));
}
Compile error
error[E0597]: `parent.counter` does not live long enough
--> src\main.rs:19:9
|
13 | let mut parent = ParentComponent {
| ---------- binding `parent` declared here
...
18 | parent.button.on_click = Some(Box::new(|| {
| - -- value captured here
| ___________________________________|
| |
19 | | parent.counter += 1;
| | ^^^^^^^^^^^^^^ borrowed value does not live long enough
20 | | }));
| |______- coercion requires that `parent.counter` is borrowed for `'static`
21 | }
| - `parent.counter` dropped here while still borrowed
|
= note: due to object lifetime defaults, `Box<dyn FnMut()>` actually means `Box<(dyn FnMut() + 'static)>`
Replace capturing with argument
The callback need to access the mutable state. The callback can access data in 3 ways:
- Arguments.
- Capturing. It stores data inside function object.
- Global variable. It's not recommended (only use when really necessary).
Use capturing to make callback access mutable data creates circular reference. Letting callback to access mutable data via argument suits borrow checker better.
We can pass the mutable state as argument to callback, instead of letting callback capture it:
struct ParentState {
counter: u32,
}
struct ParentComponent {
button: ChildButton,
state: ParentState,
}
struct ChildButton {
on_click: Option<Box<dyn Fn(&mut ParentState) -> ()>>,
}
fn main() {
let mut parent = ParentComponent {
button: ChildButton { on_click: None },
state: ParentState { counter: 0 },
};
parent.button.on_click = Some(Box::new(|state| {
state.counter += 1;
}));
// it does a split borrow of two fields in parent
parent.button.on_click.unwrap()(&mut parent.state);
assert!(parent.state.counter == 1);
}
That method is useful when callback needs to share mutable data, not just for circular reference.
Avoid callback. Defer event handling. Event-as-data.
Apply the previous deferred mutation and mutation-as-data idea. Don't immediately call callback when event happens. Store events as data and put to a queue.
The event should use ID/handle to refer to data, without indirectly borrowing the mutable data. The event then can be notified to the components that subscribe to specific event channels. Event can be handled in a top-down manner, following ownership tree.
Incomplete code example:
enum Event {
ButtonClicked { button_id: Uuid },
// ...
}
struct ParentComponent {
id: Uuid,
button: ChildButton,
counter: u32,
}
struct ChildButton {
id: Uuid,
}
impl ParentComponent {
fn handle_event(&mut self, event: Event) -> bool {
match event {
Event::ButtonClicked { button_id } if button_id == self.button.id => {
self.counter += 1;
true
}
_ => false,
}
}
}
... // many code omitted
In backend applications, it's common to use external message broker (e.g. Kafka) to pass message. Using them also requires turning event into data.
Other circular references
Grouping two things together can create circular reference:
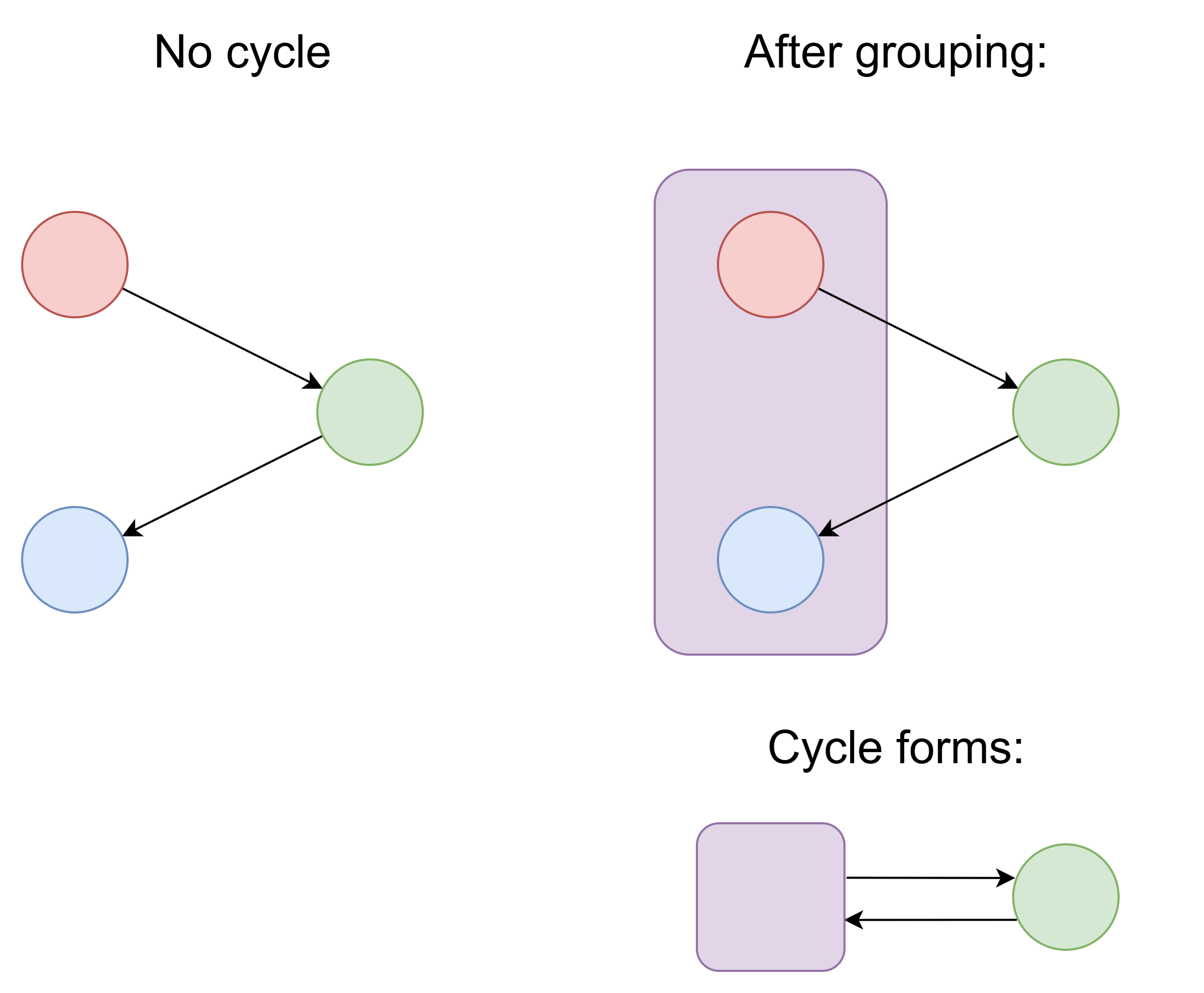
Putting two things into one struct can create new circular reference, which is unfriendly to borrow checker. No need to put one object's all data into one struct. One object's data can be scattered in many places.
In OOP languages, it's a common pattern that parent references child, and child references parent. It's convenient because you can access parent data in child's method, without passing parent as argument. That creates circular reference. This just-for-convenience circular reference should be avoided. The parent borrow should be passed as argument.
However passing parent borrow can encounter contaigous borrow issue mentioned earier. If parent owns child, you cannot mutably borrow parent and child at the same time. One workaround is to not mutably borrow the whole parent, only mutably borrow parent's fields individually (it's less convenient).
In a tree structure, if there is some logic that requires upward traverse through tree, letting child node to reference parent node is natural in non-Rust languages. It's recommended to use arena in that case.
In C++ there is the unregister-from-parent-on-destruct pattern: the parent keep a container of child object pointers; in child object's destructor, it removes itself from parent's container. This pattern also involves circular reference. This should be avoided in Rust. The child should be owned by parent, and destructing child should be done via parent.
Although circular reference is convenient in GC languages, it still has memory leak risk: when every child references parent, keeping a reference to one node of whole structure will prevent the whole structure from being GCed. In GC languages, the capturing of closure (lambda expression) are one common source of memory leaks, as the capturing is not obvious 9.
The circular reference that's inherent in data structure
If the data structure inherently requires circular reference, solutions:
- Use arena. Use ID/handle to replace borrow (elaborated later). This is the recommended solution.
- Use reference counting and interior mutability (not recommended).
- Use
unsafe(only use if really necessary).
Self-reference
Self-reference means a struct contains an interior pointer to another part of its own data.
Some crates for providing safe interface of using self-reference:
There is Pin for avoiding an object from being moved in memory. Normal Rust mutable borrow allow moving the value out (by mem::replace, or mem::swap, etc.). Pin is hard to use. If you have a pinned object reference, you cannot get the pinned field reference without unsafe, unless using pin_project. Also auto reborrow doesn't work for Pin.
The problems of Pin aim to be solved in Move trait and in-place initialization.
Pin also appears in futures. Because an async function may have a local variable reference another local variable, and local variables can be put into Future state machines, so the Future will have self-reference.
Use handle/ID to replace borrow
Data-oriented design:
- Try to pack data into contagious array, (instead of objects laid out sparsely managed by allocator).
- Use handle (e.g. array index) or ID to replace reference.
- Decouple object ID with memory address. An ID can be saved to disk and sent via network, but a pointer cannot (the same address cannot be used in another process or after process restart, because there may be other data in the same address).
- The different fields of the same object doesn't necessarily need to be together in memory. The one field of many objects can be put together (parallel array).
- Manage memory based on arenas.
Some may think that using handle/ID is "just a workaround caused by borow checker". However, in GC languages, using ID to refer to object is also common, as reference cannot be saved to database or sent via network. 10
Arena
One kind of arena is slotmap. It's generational arena.
SlotMap is similar to an array of elements, but each slot has a generation integer. If a slot's element is dropped and new element is placed in same slot, the generation counter increases.
Each handle (key) has an index and a generation integer. It's Copy-able data that's not restricted by borrow checker. Accessing slotmap only succeedes if slot generation matches.
Although memory safe, it still has the equivalent of "use-after-free": using a handle of an already-removed object cannot get element from the slotmap 11. Each get element operation may fail.
Note that SlotMap is not efficient when there are many unused empty space between elements. If there is large sparcity in IDs, using map is more appropriate.
Other kinds of arenas:
- The containers including
Vec,HashMapandTreeMapcan be treated as arenas. - append_only_vec. Its insertion only requires immutable borrow, because insertion doesn't move other elements, unlike
Vec. This feature can workaround contagious borrow issue. It uses segmented array data structure. It doesn't allow removing element or directly mutating element. - generational_box
- bevy_ecs
The important things about arena:
- The borrow checker no longer ensure the ID/handle points to a living object. Each data access to arena may fail. There is equivalent of "use after free".
- Arenas still suffer from contagious borrow issue. Mutably borrowing one element in arena mutably borrows whole arena. The previously mentioned solutions (deferred mutation, shallow clone, manual container loop, persistent data structure, etc.) may be needed.
Some may think "using arena cannot protect you from equivalent of 'use after free' so it doesn't solve problem". But arena can greatly improve determinism of bugs, making debugging much easier. A randomly-occuring memory safety Heisenbug may no longer trigger when you enable sanitizer, as sanitizer can change timing and memory layout.
Using simple array-based arena enables other optimizations: the map whose key is id can be implemented as an array; the set whose key is id can be implemented as a bitset.
There is no need to put one object's data into one struct. One object's data can be separated into many arenas. This is one idea behind ECS (entity component system). The separation can also enable free composition that's not allowed by OOP inheritance.
About linked list
In Rust, writing a pointer-based linked list is hard. Writing zero-cost pointer-based doubly-linked list in safe Rust is impossible.
But that only applies to pointer-based linked list. The conventional pointer-based linked list often has bad cache locality (because it uses global allocator, nodes may scatter in memory space).
Writing arena-based linked list in Rust is easy. And it can have better cache locality. And you can use 32-bit index instread of 64-bit pointer which also improves cache locality by reducing space usage.
The pointer-based linked list can also be optimized by making one node hold many elements.
Handle Debug
There is an ergonomic issue when using arena. The object handle is just an ID. The handle's Debug::fmt by default just outputs the ID. But just the integer ID is not helpful for debugging. We want the handle debug string to also contain object info.
But it's not easy to access the arena in handle Debug::fmt. You cannot access the arena from just handle. Possible solutions:
- Create extra "handle with context" type for debug logging.
- Put arena reference to thread local variable. The scoped_tls crate can help. This requires arena to have interior mutability. This solution is recommended for only append-only arenas. 12
Mutable borrow exclusiveness
As previously mentioned, Rust has mutable borrow exclusiveness:
- A mutable borrow to one object cannot co-exist with any other borrow to the same object. (Two mutable borrows cannot co-exist. One mutable and one immutable also cannot co-exist.)
- Multiple immutable borrows for one object can co-exist.
That is also called "mutation xor sharing", as mutation and sharing cannot co-exist.
In multi-threading case, this is natural: multiple threads read the same immutable data is fine. As long as one thread mutates the data, other thread cannot safely read or write it without other synchronization (atomics, locks, etc.).
But in single-threaded case, this restriction is not natural at all. No mainstream language (other than Rust) has this restriction.
Mutation xor sharing is, in some sense, neither necessary nor sufficient. It’s not necessary because there are many programs (like every program written in Java) that share data like crazy and yet still work fine. It’s also not sufficient in that there are many problems that demand some amount of sharing – which is why Rust has “backdoors” like
Arc<Mutex<T>>,AtomicU32, and—the ultimate backdoor of them all—unsafe.
Mutable borrow exclusiveness is still important for safety of interior pointer, even in single thread:
Interior pointer
Rust has interior pointer. Interior pointer are the pointers that point into some data inside another object. A mutation can invalidate the memory layout that interior pointer points to.
For example, you can take pointer of an element in Vec. If the Vec grows, it may allocate new memory and copy existing data to new memory, thus the interior pointer to it can become invalid. Mutation breaks the memory layout that interior pointer points to. Mutable borrow exclusiveness can prevent this issue from happening:
fn main() {
let mut vec: Vec<u32> = vec!(1, 2, 3);
let interior_pointer: &u32 = &vec[0];
vec.push(4);
print!("{}", *interior_pointer);
}
Compile error:
3 | let interior_pointer: &u32 = &vec[0];
| --- immutable borrow occurs here
4 | vec.push(4);
| ^^^^^^^^^^^ mutable borrow occurs here
5 | print!("{}", *interior_pointer);
| ----------------- immutable borrow later used here
(Related: append_only_vec doesn't move element on insertion. Interior pointers are kept valid after insertion. So its insertion doesn't require mutable borrow.)
Another example is about enum: interior pointer pointing inside enum can also be invalidated, because different enum variants has different memory layout. In one layout the first 8 bytes is integer, in another layout the first 8 bytes may be a pointer. Treating an arbitrary integer as a pointer is definitely not memory-safe.
enum DifferentMemoryLayout {
A(u64, u64),
B(String)
}
fn main() {
let mut v: DifferentMemoryLayout = DifferentMemoryLayout::A(1, 2);
let interior_pointer: &u64 = match v {
DifferentMemoryLayout::A(ref a, ref b) => {a}
DifferentMemoryLayout::B(_) => { panic!() }
};
v = DifferentMemoryLayout::B("hello".to_string());
println!("{}", *interior_pointer);
}
Compile error:
9 | DifferentMemoryLayout::A(ref a, ref b) => {a}
| ----- `v` is borrowed here
...
12 | v = DifferentMemoryLayout::B("hello".to_string());
| ^ `v` is assigned to here but it was already borrowed
13 | println!("{}", *interior_pointer);
| ----------------- borrow later used here
Note that mutation doesn't always break the memory layout that interior pointer points to. For example, changing an element in Vec<u32> doesn't invalidate interior pointer to elements, because there is no memory layout change. But Rust by default prevents all mutation when interior pointer exists (unless using interior mutability).
Interior pointer in other languages
Golang also supports interior pointer, but doesn't have such restriction. For example, interior pointer into slice:
package main
import "fmt"
func main() {
slice := []int{1, 2, 3}
interiorPointer := &slice[0]
slice = append(slice, 4)
fmt.Printf("%v\n", *interiorPointer)
fmt.Printf("old interior pointer: %p new interior pointer: %p\n", interiorPointer, &slice[0])
}
Output
1
old interior pointer: 0xc0000ac000 new interior pointer: 0xc0000ae000
Because after re-allocating the slice, the old slice still exists in memory (not immediately freed). If there is an interior pointer into the old slice, the old slice won't be freed by GC. The interior pointer will always be memory-safe (but may point to stale data).
Golang also doesn't have sum type, so there is no equivalent to enum memory layout change in the previous Rust example.
Also, Golang's doesn't allow taking interior pointer to map entry value, but Rust allows. Rust's interior pointer is more powerful than Golang's.
In Java, there is no interior pointer. So no memory safety issue caused by interior pointer.
But in Java there is one thing logically similar to interior pointer: Iterator. Mutating a container can cause iterator invalidation:
public class Main {
public static void main(String[] args) {
List<Integer> list = new ArrayList<>();
list.add(1);
Iterator<Integer> iterator = list.iterator();
while (iterator.hasNext()) {
Integer value = iterator.next();
if (value < 3) {
list.remove(0);
}
}
}
}
That will get java.util.ConcurrentModificationException. Java's ArrayList has an internal version counter that's incremented every time it changes. The iterator code checks concurrent modification using version counter. (Even without the version check, it will still be memory-safe because array access is range-checked.)
Note that the container for loop in java internally uses iterator (except for raw array). Inserting or removing to the container while for looping can also cause iterator invalidation.
Note that iteration invalidation is logic error, no matter whether it's memory-safe or not.
In Java, you can remove element via the iterator, then the iterator will update together with container, and no longer invalidate. Or use removeIf that avoids managing iterator.
To summarize, mutable borrow exclusiveness is overly strict in single-threaded case:
- If we don't use any interior pointer, then mutation cannot cause memory safety issue. (Example: Java has no interior pointer)
- Even when we use interior pointer, as long as mutation doesn't change memory layout, it's still memory-safe. (Example: Golang interior pointer)
That's why mainstream languages has no mutable borrow exclusiveness, and still works fine in single-threaded case. Java, JS and Python has no interior pointer. Golang and C# have interior pointer, they have GC and restrict interior pointer, so memory safe is still kept without mutable borrow exclusiveness.
There are design ideas of separting the mutation that change memory layout and the mutation that doesn't change memory layout. See also: An alternative model for "lifetimes" in Mojo, Ante: A New Way to Blend Borrow Checking and Reference Counting, Carbon memory safety
Having the borrow vs using the borrow
When you have two mutable borrows to same object and you use both, it can be unsafe (invalidate interior pointer, data race, etc.). However, if you have two mutable borrows but only use one at once, then it's safe. The reborrow (mentioned below) does that.
Rust "confuses" having borrow and using borrow (except in reborrow). Tracking that in type system needs to encode information that "this borrow exists but it is temporarily unusable in a specific lifetime", which would introduce complexity. Rust design chooses to simplify it by assuming all borrows may be used.
Benefits of mutable borrow exclusiveness
Rust's mutable borrow exclusiveness creates a lot of troubles in single-threaded cases. But it also has benefits (even in signle-threaded cases):
- Make the borrow more universal. In Rust, map key and value can be borrowed. But in Golang you cannot take interior pointer to map key or value. This makes abstractions that work with borrows more general.
- Mutable borrow is exclusive, so Rust can emit LLVM
noaliasattribute (in release mode).noaliasmeans the pointed data cannot be accessed by other code, which helps optimizations. When optimizer knows no other pointer can equal to that pointer, then reads can be merged, writes can be merged, and its read/write can be reordered between other computations. Then there will be more optimization opportunities. 13
Related: CPU internally optimizes by assuming two seprately-calculated addresses are different (assuming no alias), then rollback if assumption is wrong. This is called Memory disambiguation.
Related: in C, the same optimization opportunity can be enabled by restrict keyword, which corresponds to LLVM noalias. Note that C++ standard doesn't have this feature.
Interior mutability summary
Mutable borrow exclusiveness is overly restrictive. It is not necessary for memory safety in single-threaded code when not using interior pointer. There is interior mutability that allows getting rid of that constraint.
Interior mutability allows you to mutate something from an immutable reference to it. (Because of that, immutable borrow doesn't necessarily mean the pointed data is actually immutable. This can cause some confusion.)
Ways of interior mutability:
Cell<T>. It's suitable for simple copy-able types like integer. 14RefCell<T>, suitable for data structure that does incremental mutation, in single-threaded cases. It has internal counters tracking how many immutable borrow and mutable borrow currently exist. If it detects violation of mutable borrow exclusiveness,.borrow()or.borrow_mut()will panic.It can cause crash if there is nested borrow that involves mutation.Mutex<T>RwLock<T>, for locking in multi-threaded case. Its functionality is similar toRefCell. Note that unnecessary locking can cost performance, and has risk of deadlock. It's not recommended to overuseArc<Mutex<T>>just because it can satisfy the borrow checker.QCell<T>. Elaborated below.- Atomic types such as
AtomicU32 UnsafeCell<T>- Lazily-initialized
OnceCell<T> - ......
They are usually used inside reference counting (Arc<...>, Rc<...>).
RefCell is not panacea
In the previous contagious borrow case, wrapping parent in RefCell<> can make the code compile. However it doesn't fix the issue. It just turns compile error into runtime panic:
use std::cell::RefCell;
pub struct Parent { total_score: u32, children: Vec<Child> }
pub struct Child { score: u32 }
impl Parent {
fn get_children(&self) -> &Vec<Child> {
&self.children
}
fn add_score(&mut self, score: u32) {
self.total_score += score;
}
}
fn main() {
let parent: RefCell<Parent> = RefCell::new(Parent{total_score: 0, children: vec![Child{score: 2}]});
for child in parent.borrow().get_children() {
parent.borrow_mut().add_score(child.score);
}
}
It will panic with RefCell already borrowed error.
RefCell still follows mutable borrow exclusiveness rule, just checked at runtime, not compile time. Borrowing one field inside RefCell still borrows the whole RefCell.
Wrapping parent in RefCell cannot fix contagious borrow, but putting individual children into RefCell can work, as it makes borrow more fine-grained.
Related: Dynamic borrow checking causes unexpected crashes after refactorings
Rust assumes that, if you have a mutable borrow &mut T, you can use it at any time. But holding the reference is different to using reference. There are use cases that I want to have two mutable borrows to the same object, but I only use one at a time. This is the use case that RefCell solves.
Returning borrow inside RefCell
The RefCell can cause other troubles. The borrow taken from RefCell cannot be directly returned. Example:
pub struct Arena<T> {
items: RefCell<Vec<T>>,
}
impl<T> Arena<T> {
fn at(&self, i: usize) -> &T {
&self.items.borrow()[i]
}
}
It will compile error "cannot return value referencing temporary value". Because the .borrow() doesn't return a normal borrow. It returns Ref. Ref implements Deref so it can be used similar to a normal borrow.
The Ref does some extra thing on drop (decrement counter in RefCell), so the lifetime of Ref needs to be considered.
One solution is to returnRef and use Ref::map:
pub struct Arena<T> {
items: RefCell<Vec<T>>,
}
impl<T> Arena<T> {
fn at(&self, i: usize) -> Ref<T> {
Ref::map(self.items.borrow(), |v| &v[i])
}
}
This makes Ref appear in function signature. It makes encapsulation "leaky". And the Ref::map is not ergonomic.
Summarize the two downsides of RefCell:
- When contagious borrow occurs, it doesn't cause compile error but causes runtime panic.
- Returning borrow inside
RefCellforces changing of function signature, making encapsulation "leaky".
The similar applies to Mutex. And the problem of Mutex is even larger than RefCell:
- Borrow conflict in
RefCellcauses panic. But borrow conflict inMutexcauses deadlock. Deadlock is harder to debug than panic. - Performance issue.
Mutexis slow when contended by multiple threads. While performance cost ofRefCellis small.
Only use Mutex when you want locking. Don't use Arc<Mutex<>> just for evading borrow check restriction.
QCell
QCell<T> has an internal ID. QCellOwner is also an ID. You can only use QCell via an QCellOwner that has matched ID.
The borrowing to QCellOwner "centralizes" the borrowing of many QCells associated with it, ensuring mutable borrow exclusiveness. Using it require passing borrow of QCellOwner in argument everywhere it's used.
QCell will fail to borrow if the owner ID doesn't match. Different to RefCell, if owner ID matches, it won't panic just because of nested borrow.
Its runtime cost is low. When borrowing, it just checks whether cell's id matches owner's id. It has memory cost of owner ID per cell.
One advantage of QCell is that borrow conflict will be compile-time error instead of runtime panic, which helps catch error earlier. If I change the previous RefCell panic example into QCell:
pub struct Parent { total_score: u32, children: Vec<Child> }
pub struct Child { score: u32 }
impl Parent {
fn get_children(&self) -> &Vec<Child> { &self.children }
fn add_score(&mut self, score: u32) { self.total_score += score; }
}
fn main() {
let owner: QCellOwner = QCellOwner::new();
let parent: QCell<Parent> = QCell::new(&owner, Parent{total_score: 0, children: vec![Child{score: 2}]});
for child in parent.ro(&owner).get_children() {
parent.rw(&mut owner).add_score(child.score);
}
}
Compile error:
17 | for child in parent.ro(&owner).get_children() {
| --------------------------------
| | |
| | immutable borrow occurs here
| immutable borrow later used here
18 | parent.rw(&mut owner).add_score(child.score);
| ^^^^^^^^^^ mutable borrow occurs here
It turns runtime panic into compile error, which make discovering problems eariler.
GPUI's Model<T> is similar to Rc<QCell<T>>, where GPUI's AppContext correspond to QCellOwner.
Directly using Arc<QCell<>> is not convenient. GPUI has many wrappers that make it more convenient.
It can also work in multithreading, by having RwLock<QCellOwner>. This can allow one lock to protect many pieces of data in different places 15.
Ghost cell and LCell are similar to QCell, but use closure lifetime as owner id. They are zero-cost, but more restrictive (owner is tied to closure scope, cannot dynamically create, owner cannot outlive closure).
Note that QCell still suffers from contagious borrow: after mutably borrowing one QCell under a QCellOwner, you cannot borrow another QCell under the same QCellOwner, except when using special multi-borrow like rw2.
Rust lock is not re-entrant
Re-entrant lock means one thread can lock one lock, then lock it again, then unlock twice, without deadlocking. Rust lock is not re-entrant. (Rust lock is also responsible for keeping mutable borrow exclusiveness. Allowing re-entrant can produce two &mut for same object.)
For example, in Java, the two-layer locking doesn't deadlock:
public class Main {
public static void main(String[] args) {
Object lock = new Object();
synchronized (lock) {
synchronized (lock) {
System.out.println("within two layers of locking");
}
}
System.out.println("finish");
}
}
But in Rust the equivalent will deadlock:
fn main() {
let mutex: Mutex<u64> = Mutex::new(0);
{
let mut g1: MutexGuard<u64> = mutex.lock().unwrap();
{
println!("going to do second-layer lock");
let mut g2 = mutex.lock().unwrap();
println!("within two layers of locking");
}
}
println!("finish");
}
It prints going to do second-layer lock then deadlocks.
In Rust, it's important to be clear about which scope holds lock. Golang lock is also not re-entrant.
Another important thing is that Rust only unlocks at the end of scope by default. mutex.lock().unwrap() gives a MutexGuard<T>. MutexGuard implements Drop, so it will drop at the end of scope. It's different to the local variables whose type doesn't implement Drop, they are dropped after their last use (unless borrowed). This is called NLL (non-lexical lifetime).
Arc is not always fast
Cloning and dropping Arc involves atomic operations of changing reference count. When many threads frequently change the same atomic counter, performance can degrade.
Modern CPUs use cache coherency protocol (e.g. MOESI). Atomic operations often require the CPU core to hold "exclusive ownership" to cache line (this may vary between different hardware). Many threads frequently doing so cause cache contention, similar to locking, but on hardware.
Examples:
- The Concurrency Trap: How An Atomic Counter Stalled A Pipeline
- How a Single Line of Code Made a 24-core Server Slower Than a Laptop
Using Arc wrongly may result in slower performance than using GC languages. In GC languages, reading an on-heap reference often only involve a simple memory read 16, without atomic read-modify-write operation.
Atomic reference counting is still fast if not contended (when mostly only one thread change reference count). Atomic reference counting is faster on Apple silicon than Intel CPUs. 17
But don't worry too much about Arc. In most normal applications, Arc itself likely won't be the bottleneck18. Swift uses atomic reference counting almost everywhere and it's mostly fine. Profile before doing optimization.
If Arc clone/dropping do become bottleneck, possible solutions:
- For frequent short-term reads to mutable data, use arc_swap. It follows read-copy-update (RCU) or copy-on-write (COW) paradigm. In RCU(or COW), mutation requires recreating the whole data structure, and atomically change the root pointer, with delayed dropping mechanism (arc_swap uses hazard pointer).
- Other solutions of delayed dropping that avoids overhead of atomic reference counting: sdd, crossbeam_epoch
- Deep cloning data instead of sharing
Arc. - If the data is global sigleton, can just put it to global
static(useOnceLockfor delayed initialization). For short-running programs like CLI, leaking it is fine. - trc and hybrid_rc. Use per-thread non-atomic counter together with atomic counter.
- Shard the counter. Given an
Arc<T>, clone many instances then wrap each asArc<CachePadded<Arc<T>>>19. Send differnt two-layer-arcs to different threads. There will be fewer contention as different CPU cores likely touch different atomic counters.
Reference counting vs tracing GC
There are some ambiguity of the word "GC". Some say reference counting is GC, some say it isn't.
No matter what the definition of "GC" is, reference counting is different from tracing GC (in Java/JS/C#/Golang/etc.):
| Reference counting | Tracing GC |
|---|---|
| Frees memory immediately | Frees in deferred and batched way 20 |
| Freeing a whole large structure may cause large lag 21 | Require more memory to achieve high performance, otherwise GC lag will be large. |
| Finds greatest fixed point | Finds least fixed point |
| Propagates "death". (freeing one object may cause its children to be freed) | Propagates "live". (a living object cause its children to live, except for weak reference) |
Cloning and dropping a reference involves atomic operation (except single-threaded Rc) | Reading/writing an on-heap reference may involve read/write barrier (often a branch, no atomic memory access) |
| Cannot automatically handle cycles. Need to use weak reference to cut cycle | Can handle cycles automatically |
| Cost is roughly O(reference count changing frequency) 22 | Cost is roughly O(count of living objects * GC frequency) 23 |
Bump allocator
bumpalo provides bump allocator. In bump allocator, allocation is fast because it usually just increase an integer. It supports quickly freeing the whole arena, but doesn't support freeing individual objects.
It's usually faster than normal memory allocators. Normal memory allocator will do a lot of bookkeeping work for each allocation and free. Each individual memory region can free separately, these regions can be reused for later allocation, these information need to be recorded and updated.
Bump allocator frees memory in batched and deferred way. As it cannot free individual objects, it may temporarily consume more memory.
Bump allocator is suitable for temporary objects, where you are sure that none of these temporary objects will be needed after the work complets.
The function signature of allocation (changed for clarity):
impl Bump {
...
pub fn alloc<T, 'bump>(&'bump self, val: T) -> &'bump mut T { ... }
}
It takes immutable borrow of Bump (it has interior mutability). It moves val into the bump-allocated memory region. It outputs a mutable borrow, having the same lifetime as bump allocator. That lifetime ensures memory safety (cannot make the borrow of allocated value outlive bump allocator).
If you want to keep the borrow of allocated result for long time, then lifetime annotation is often required.
In Rust, lifetime annotation is also contagious. Every struct that holds bump-allocated borrow need to also have lifetime annotation of the bump allocator. Every function that use it also needs lifetime annotation. Lifetime elision can help in some cases but it doesn't cover non-trivial cases.
Adding or removing lifetime for one thing may involve editing tons of related code. It can be huge work before AI. But with AI, adding/removing lifetime annotation to many places is easy.
yoke allows getting rid of lifetime annotation by combining bump-allocated structure together with the bump allocator.
It's recommended to have separated bump allocator in each thread locally. The Bump is not Sync and cannot be shared between threads.
Note that bumpalo by default don't run drop to improve performance. Use bumpalo::boxed::Box<T> for things that require invoking drop.
Using unsafe
By using unsafe you can freely manipulate pointers and are not restricted by borrow checker. But writing unsafe Rust is harder than just writing C/C++, because you need to carefully avoid breaking the constraints that safe Rust code relies on. A bug in unsafe code can cause issue in safe code.
Writing unsafe Rust correctly is hard. Here are some traps in unsafe:
- Don't violate mutable borrow exclusiveness.
- A
&mutshould not overlap with any other borrows and raw pointers. Including temporary borrows. Note thatobj.method()can implicity create borrow toobj. - Violating that rule cause undefined behavior(UB) and can cause wrong optimization. Rust adds
noaliasattribute for mutable borrows into LLVM IR. LLVM will heavily optimize based onnoalias. See also - Multiple mutable raw pointers
*mut Tcan point to same data. But raw pointer cannot coexist with mutable borrow to same data. - Related1, Related2
- Also, the type that has self-reference should be
!Unpin. IfTis!Unpinthen&mut Thas nonoalias. (However, there is still potential unsoundness related to self-reference)
- A
- Converting a
&Tto*mut Tthen mutate pointed data is undefined behavior, unless withinUnsafeCell. In release mode,&Thas LLVMreadonlyattribute which can enable some optimizations, but ifTcontainsUnsafeCellthen compiler won't addreadonly. - Pointer provenance.
- For to-heap pointers, different heap allocations are different provenances. Different local variables and global variables are different provenances. If two pointers with two different provenances are equal, it is undefined behavior.
- The XOR linked list breaks under pointer provenance and should not be used.
- Recording offset between two pointers then add offset only works within one provenance.
- The provenance is analyzed by compiler at compile time. In actual execution, pointers are just integers that doesn't attach provenance information 24.
- Using uninitialized memory is undefined behavior.
MaybeUninit- Normally a byte has 256 possible values. But in LLVM a byte has 258 possible values 25. The extra two are 1. uninitialized 2. poison (computed from other undefined behaviors). Like pointer provenance, the two extra values only exist at compile time.
a = bwill drop the original object in place ofa(unless whenais a local variable that was moved-out). Ifais uninitialized, then it will drop an unitialized object, which is undefined behavior. Use(&raw mut a).write(...)Related- Handle panic unwinding. If unsafe code turn data into temporarily-invalid state, you need to make it valid again during unwinding. See also. Related
- In Rust, future can poison. This is different to lock poison. When an async function panics, the future should go into "poison state", all internal data should be dropped, then polling it again should panic. This needs to be considered when manually implementing
Futuretrait.
- In Rust, future can poison. This is different to lock poison. When an async function panics, the future should go into "poison state", all internal data should be dropped, then polling it again should panic. This needs to be considered when manually implementing
- Reading/writing to mutable data that's shared between threads need to use atomic, or volatile access (
read_volatile,write_volatile), or use other synchronization (like locking). If not, optimizer may wrongly merge and reorder reads/writes. In MMIO (memory-mapped IO), all memory accesses should use volatile access. Note that volatile accesses themselves don't establish memory order (unlike Java/C#volatile). - If the binary data violates the type's constraint, it's undefined behavior. For example,
bool's binary data can only be 0 or 1. Making it 2 is undefined behavior. Creating astrwhose binary data is not valid UTF-8 is also undefined behavior. - If you want to
mem::transmute, it's recommended to use zerocopy which has compile-time checks to ensure memory layout are the same. - ......
Modern compilers tries to optimize as much as possible. To optimize as much as possible, the compiler makes assumptions as much as possible. Breaking any of these assumption can lead to wrong optimization. That's why it's so complex. See also: C Is Not a Low-level Language
Unfortunately Rust's syntax ergonomics on raw pointer is currently not good:
- If
pis a raw pointer, you cannot writep->field(like in C/C++), and can only write(*p).field. (This will be addressed in field projections) - Raw pointer cannot be method receiver (self). (This is addressed in unstable feature arbitrary_self_types)
- There is raw pointer to slice, but it doesn't support indexing syntax
s[i]. You need to manually.add()pointer and dereference. Bound checking is also manual. (Converting raw pointer to slice borrow enables convenient indexing syntax, but it is prone to aliasing UB as mentioned previously)
No "temporary void" of borrowed data
In safe Rust, the borrowed data has to be always valid. You cannot make borrowed data become "temporary void" then fill the void.
Example:
enum SomeState {
State1(Vec<u8>),
State2(Vec<u8>),
}
fn do_some_state_transfer(state: &mut SomeState) {
// State1 transfer to State2, State2 stays the same
match state {
SomeState::State1(data) => {
*state = SomeState::State2(*data);
}
SomeState::State2(_) => {}
}
}
Compile error
error[E0507]: cannot move out of `*data` which is behind a mutable reference
--> src\main.rs:22:40
|
22 | *state = SomeState::State2(*data);
| ^^^^^ move occurs because `*data` has type `Vec<u8>`, which does not implement the `Copy` trait
|
help: consider cloning the value if the performance cost is acceptable
|
22 - *state = SomeState::State2(*data);
22 + *state = SomeState::State2(data.clone());
|
We often don't want to clone the data because it costs performance.
One workaround is to use functional style. Instead of doing mutation, it takes ownership of old state then return new state:
// this compiles
fn do_some_state_transfer(state: SomeState) -> SomeState {
// State1 transfer to State2, State2 stays the same
match state {
SomeState::State1(data) => SomeState::State2(data),
x @ SomeState::State2(_) => x,
}
}
But this involves the previously mentioned contagious-recreate-parent problem. The outer structure that contains it also needs to be re-created. In many cases, it cannot be done or it is very inconvenient.
Another workaround is to use Arc to hold the data. Then cloning is cheap. But then mutating inner data is a problem (if you ensure the reference count is always 1 when mutating, then get_mut can be used).
Another workaround is to swap it with a default value using mem::take:
match state {
SomeState::State1(data) => {
*state = SomeState::State2(mem::take(data));
}
SomeState::State2(_) => {}
}
The mem::take internally uses mem::replace to replace it with default value:
pub const fn take<T: [const] Default>(dest: &mut T) -> T {
replace(dest, T::default())
}
And mem::replace internally uses unsafe:
pub const fn replace<T>(dest: &mut T, src: T) -> T {
unsafe {
let result = crate::intrinsics::read_via_copy(dest);
crate::intrinsics::write_via_move(dest, src);
result
}
}
mem::swap or mem::replace cannot be implemented in safe Rust because it involves creating borrowed "temporary void".
There is a "make illegal state unrepresentable" principle: prevent the invalid data from being created in memory, thus reduce chance of bugs. But workarounding that problem by mem::replace force you to add a special state that does not represent valid data, which conflicts with "make illegal state unrepresentable". Related closed RFC.
This restriction is related to panic unwinding. Before the "temporary void" becomes valid again, panic unwinding can cause function to exit early and never fill the void. See also.
Note that the restriction only applies to borrowed data. A local variable that's not borrowed can be temporary moved-out then re-assigned.
Unintuitive Send and Sync
The Send and Sync are not intuitive. Someone learning Rust may ask "String has no internal synchronization, so it's definitely not thread-safe, why does it satisfy Send and Sync?" Because Send and Sync actually tests on interior mutability. The underlying logic is not simple:
- If the data structure is fully tree-shaped, no sharing is possible. Each object is owned by exactly one thread. So it's thread-safe. But this brekas when
Rcmakes data not tree-shaped. TwoRcstructs can internally reference one object, but from the "outside" oneRcis just one struct that fits in tree-shaped ownership. - Even if there is sharing, only immutable borrow can be shared. If the shared data is actually immutable, then it's thread-safe. But this breaks with interior mutability. With interior mutability, it can be mutated via immutable borrow.
The String has no interior mutability. So the tree-shaped ownership and mutable borrow exclusiveness already prevents data race of it.
If there is no interior mutability (Rc uses interior mutability), then all data are thread safe, Send and Sync is not needed. The Send and Sync is used for checking the exceptions caused by interior mutability.
Then why there are two traits Send and Sync, rather than only one trait? Because transfering ownership betwene threads is differnet to sharing between different threads. RefCell owns the data and can be transferred to another thread, but multiple threads sharing one RefCell is unsafe because RefCell doesn't do synchronization, so RefCell is Send but not Sync.
Send + 'static
Tokio is a popular async runtime. In Tokio, submitting a task require the future to be Send and 'static.
pub fn spawn<F>(future: F) -> JoinHandle<F::Output>
where
F: Future + Send + 'static,
F::Output: Send + 'static,
-
'staticmeans it's standalone (self-owned). It doesn't borrow temporary things. It can borrow global values (global values will always live when program is running).The spawned future may be kept for a long time. It's not determined whether future will only temporarily live within a scope. So the future need to be
'static. tokio_scoped allows submitting a future that's not'static, but it must be finished within a scope.If the future need to share data with outside, pass
Arc<T>into (not&Arc<T>). -
Sendmeans that the future can be sent across threads. Tokio use work-stealing, which means that one thread's task can be stolen by other threads that currently have no work.Sendis not needed if the async runtime doesn't move future between threads.
Rust converts an async functions into a state machine, which is the future object. In async function, the local variables that are used across await points will become fields in future. If the future is required to be Send then these local variables also need to be Send.
Note that the "static" in C/C++/Java/C# often mean global variable. In Rust its meaning is similar but different. static x still declares global value. Borrows to global values have lifetime 'static. But the standalone values (self-owned, don't borrow temporary things) also have 'static lifetime, although they are not global values and don't live forever.
In Rust 'static just mean its lifetime is not limited to a specific scope. It doesn't necessarily mean it will live forever. 'static is the bottom type 26 of lifetimes, similar to never in TypeScript. It's called 'static just because global values' lifetime is coincidentally also bottom type, so the same naming is reused.
"Lifetime" is not "lifetime"
The "lifetime" in Rust has nuanced distinction between the real "lifetime" of data:
-
The lifetime is just a constraint. Lifetime of a borrow can be shortened. Shortening lifetime makes constraint looser. Expanding lifetime is makes constraint stricter.
-
The lifetime constraints when the data dies, but doesn't constraint when the data is crated. You can leak some data and get a
'staticborrow to it. The'staticmeans the whole program's lifetime, but the data is not created right after program launches.Similarily, all data from one bump allocator have the same "lifetime", even though some of them is created earlier than others.
-
Lifetime is not tied to "time". It's tied to a "scope" (not necessarily explicit scope marked by
{}, it can be like "from line 5 to line 7").
The actual meaning of Rust "lifetime" is that: if I get access to that data, it constraints that the data stays valid in the scope.
Side effect of extracting and inlining variable
In C and GC languages:
- If a variable is used only once, you can inline that variable. This will only change execution order (except in short-circuit 27).
- Extracting a variable will only change execution order (except when variable is used twice or in short-circuit).
But in Rust it's different.
Lifetime of temporary value
- Putting a temporary value to local variable usually makes it live longer.
- Inlining a local variable usually makes it live shorter.
One example
let c: RefCell<Option<String>> = RefCell::new(Option::Some("hello".to_string()));
let string: &String = c.borrow().as_ref().unwrap();
println!("{}", string);
It will compile error "temporary value dropped while borrowed". Because the result of c.borrow() is a temporary value that doesn't live long enough. Solution is to make it a local variable to live longer:
let c: RefCell<Option<String>> = RefCell::new(Option::Some("hello".to_string()));
let borrowed = c.borrow();
let string: &String = borrowed.as_ref().unwrap();
println!("{}", string);
Not all temporary values need to be put into local variable. Sometimes match, if let can implicitly make temporary value live longer.
In other languages, if a local variable is only used once, it's often ok to inline it. But in Rust inlining a local variable that does borrowing can cause compile error.
Sometimes you need to introduce a new scope to avoid a non-Send thing to live across .await point.
Also note that if the local variable name is _, then it doesn't prolong lifetime.
Reborrow
Normally mutable borrow &mut T can only be moved and cannot be copied.
But reborrow is a feature that sometimes allow you to use a mutable borrow multiple times. Reborrow is very common in real-world Rust code. Reborrow is not explicitly documented. See also
Example:
fn mutate(i: &mut u32) -> &mut u32 {
*i += 1;
i
}
fn mutate_twice(i: &mut u32) -> &mut u32 {
mutate(i);
mutate(i)
}
That works. Rust will implicitly treat the first mutate(i) as mutate(&mut *i) so that i is not moved into and become usable again.
But extracting the second i into a local variable early make it not compile:
fn mutate_twice(i: &mut u32) -> &mut u32 {
let j: &mut u32 = i;
mutate(i);
mutate(j)
}
7 | fn mutate_twice(i: &mut u32) -> &mut u32 {
| - let's call the lifetime of this reference `'1`
8 | let j: &mut u32 = i;
| - first mutable borrow occurs here
9 | mutate(i);
| ^ second mutable borrow occurs here
10 | mutate(j)
| --------- returning this value requires that `*i` is borrowed for `'1`
Reborrow shows that you actually can have two mutable borrows to same object at the same time, but at most one can be "active" at a time. The others have to be "temporarily inactive".
Move cloned data into closure
tokio::spawn require future to be standalone and doesn't borrow other things ('static).
Passing passing an Arc (that's used later) into moved closure makes closure borrow the Arc. The data that contains borrow is not standalone (not 'static).
#[tokio::main]
async fn main() {
let data: Arc<u64> = Arc::new(1);
let task1_handle = tokio::spawn(async move {
println!("From task: Data: {}", *data);
});
println!("From main thread: Data: {}", *data);
}
Compile error
6 | let data: Arc<u64> = Arc::new(1);
| ---- move occurs because `data` has type `Arc<u64>`, which does not implement the `Copy` trait
7 |
8 | let task1_handle = tokio::spawn(async move {
| ---------- value moved here
9 | println!("From task: Data: {}", *data);
| ---- variable moved due to use in coroutine
...
12 | println!("From main thread: Data: {}", *data);
| ^^^^ value borrowed here after move
Manually clone the Arc<T> and put it into local variable works. It will make the cloned version to move into future:
#[tokio::main]
async fn main() {
let data: Arc<u64> = Arc::new(1);
let data2 = data.clone(); // this is necessary
let task1_handle = tokio::spawn(async move {
println!("From task: Data: {}", *data2);
});
println!("From main thread: Data: {}", *data);
}
The new local variable let data2 = data.clone(); is necessary. When there are many such things, it can be cumbersome to write and read. There is a proposal on improving syntax ergonomic of it.
Nuance of "immutable"
There are 3 kinds of "immutable":
- Fully-immutable. The referenced object is immutable, and the reference is also immutable.
- Mutable-ref-to-immutable-obj. The referenced object is immutable, but the reference itself is mutable.
- Immutable-ref-to-mutable-obj. The referenced object is mutable, but the reference itself is immutable.
Note that read-only is different to immutable.
Examples:
- Java
finalreference ensures reference itself is immutable. If pointed object is mutable then its's immutable-ref-to-mutable-obj. - Java
Collections.unmodifiableList()gives read-only view. - Copy-on-write (COW) and read-copy-write (RCU) are mutable-ref-to-immutable-obj.
- Rust
let x: Tmakesxfully immutable28. Immutability applies to whole ownership tree. If aVecis immutable, its elements are also immutable. - Rust
let mut x: &Tmakesxa mutable-ref-to-immutable-obj. - Rust
let x: &mut Tmakesxan immutable-ref-to-mutable-obj. - Rust
let x: &mut &[u8]makesxan immutable-ref-to-mutable-slice-ref-to-immutable-binary-data:[u8]is slice of binary data. It's a variable-sized type.&[u8]is slice ref, containing a pointer and a length.mut &[u8]is mutable slice ref. The pointer and length is mutable, but binary data in slice is immutable.xis a pointer to that mutable slice ref.xitself is immutable.- The unintuitive point is that in
&mut &it looks like "mut" is close to the left&, furthur to the right&, but themutactually applies to the right&.
- Git release tag is mutable-ref-to-immutable-obj. The Git commit with specific hash is immutable. But Git allows removing a release tag and create a new same-named release tag to another commit (this can be disabled).
String types
In GC languages, strings are simple. There is often one commonly-used immutable string type (String in java, string in JS). But in Rust there are many string types:
str, a variable-sized type. Its content should be valid UTF-8.&str, an immutable borrow tostr. It contains a pointer and a length.String. It also has a pointer and a length (and a capacity number). It heap-allocates the binary data and owns binary data.&strborrows binary data from elsewhere.OsString/OsStr. These exist because Rust string enforces UTF-8 encoding, but operating systems APIs can use non-UTF-8 string. In Linux, file name can be invalid UTF-8. In Windows APIs, strings use encoding similar to UTF-16 but allows invalid surrogates (technically called WTF-16).CString/CStr. C-style null-terminated string. Used for interop with C library.
In C++ and Golang, strings are just binary data with no encoding constraint. Rust enforces UTF-8 and makes it more complex.
Rust's enforcing of UTF-8 may improve security but may also reduce security:
- CVE-2024-56732 is triggered when non-UTF-8 string data. It's in C++. This can be avoided if the outer string source validates UTF-8. This is the case where Rust's design can improve security.
- Rust
strenforces UTF-8 so Rust code truststrto be UTF-8 and don't do internal validation. In Rust, using unsafe to create astrcontaining invalid UTF-8 is undefined behavior and can cause security risk. CVE-2026-0810 is caused by it.
Note that Rust only care about UTF-8 code point validity, not grapheme cluster validity.
About nullable string comparision: In Java you can directly Objects.equals. In JS you can directly ===. But in Rust, comparing optional strings is not trivial:
- Comparing a
Option<String>with&str:a.as_deref() == Some(b) - Comparing a
Option<&str>withString:a == Some(b.as_str()) - Comparing a
Option<String>withOption<&str>:a.as_deref() == b
The as_deref is not intuitive. It turns Option<String> into Option<&str>. The as_str turns String into &str. Rust has deref auto conversion that can auto convert &String to &str, but that auto conversion sometimes doesn't work with generics, so some as_deref as_str is required.
Summarize the contagious things
- Borrowing that cross function boundary is contagious. Just borrowing a wheel of car indirectly borrows the whole car.
- Contagious borrow between branches. If the output of a branch indirect borrows matched value, then that borrow contaminates another branch.
- Lifetime annotation is contagious. If a type has a lifetime parameter, then every type that holds it must also have lifetime parameter. Every function that use them also need lifetime parameter (except when lifetime elision works). Adding/removing lifetime parameter to a type may require big refactoring. (AI can help with this kind of refactoring.)
asyncis contagious.asyncfunction can call normal function. Normal function cannot easily callasyncfunction (it's possible to call by blocking, but faces async-sync-async sandwitch issue). Many non-blocking functions tend to become async because they may call async function.- Being not
Sync/Sendis contagious. A struct that indirectly owns a non-Syncdata is notSync. A struct that indirectly owns a non-Senddata is notSend. A reference to non-Syncdata is notSend. - Error passing is contagious. If panic is not acceptable, then all functions that indirectly call a fallible function must return
Result.- Related: NaN is contagious in floating point computation.
- Related: To handle out-of-memory gracefully in embedded system, panic unwind cannot be used, then all dependencies must be able to handle out-of-memory using
Result, see also.
- Mutate-by-recreate is contagious. Recreating child require also recreating parent that holds the new child, and parent's parent, and so on.
mutis contagious. Amutone can be treated temporarily immutable. But an immutable one cannot be treated mutable, unless using interior mutability. Sometimes it needs to have two functions one for immutable one for mutable.
Contagious effects
The "async", "mut", "Result" things can be generalized as "effects". These effects appears in types and are contagious. Why these effects are not contagious in other languages:
- The "async" effect: In Golang goroutine and Java green thread, every function is "async" implicitly.
- The "mut" effect: In mainstream GC languages there is no "object content immutability" notation in type. Things are mutable by default. (Java
finalis shallow immutability.finalis modifier, not in type). - The "Result" effect: In the languages that have exceptions, almost every function can throw exception implicitly. (Java has checked exception, which is contagious in type, but it doesn't enforce for
RuntimeExceptions)
See also: effect generics proposal.
All of the above contagious effect has "escape hatch" that's invisible in types:
| Effect that's contagious in types | "Escape hatch" that's invisible in types |
|---|---|
| "async" effect | Block the thread |
| "mut" effect | Interior mutability 29 |
| "Result" effect | Panic |
Some arguments
- "Rust doesn't ensure safety of
unsafecode. There are real vulnerabilities in Rust code: first Linux vulnerability in Rust code. So using Rust provides no value.". No. This is perfect solution fallacy. One solution being imperfect doesn't mean it's useless. If you keep the amount ofunsafesmall, you only need to inspect these small amount ofunsafecode. In C/C++ you need to inspect all related code. - "There are sanitizers in C/C++ that help me catch memory safety bugs and thread safety bugs, so Rust has no value." No. Some memory safety and thread safety bugs only trigger in production environments and in client's computers, but don't reproduce in test environment. Also there are Heisenbugs that can evade sanitizers. Elaborated below.
- Related: the Zig bun had many memory safety bugs in error case that Address Sanitizer didn't catch. There are many memory-safety bugs that only trigger in some specific error case. Large software has so many error cases, and tests can only trigger a tiny portion of them.
- "Using arena still face the equivalent of 'use after free', so arena doesn't solve the problem". No. Arenas can make these bugs much more deterministic than raw use-after-free bugs, preventing them from becoming Heisenbugs, making debugging much easier.
- "Rust borrow checker rejects your code because your code is wrong." No. Rust can reject valid safe code.
- "Circular reference is bad and should be avoided." No. Circular reference can be useful in many cases. Linux kernel has doubly linked lists. But circular reference do come with risks.
- "Rust guarantees high performance." No. If one evades borrow checker by using
Arc<Mutex<>>everywhere, the program will be likely slower than using a normal GC language (and has more risk of deadlocking). But it's easier to achieve high performance in Rust. In many other languages, achieving high perfomance often require bypassing (hacking) a lot of language functionalities. - "Rust guarantees security." No. Rust doesn't ensure memory/thread safety of
unsafecode 30. Also, not all security issues are memory/thread safety issues. According to Common Weakness Enumeration 2024, many real-world vulnerabilities are XSS, SQL injection, directory traversal, command injection, missing authentication, etc. that are not memory/thread safety. - "Rust makes multi-threading easy, as it prevents data race." No. Although Rust can prevent data race, it cannot prevent deadlocks. Async Rust also has traps including blocking scheduler thread and cancellation safety.
- "Rust doesn't help other than memory/thread safety." No.
- Algebraic data type (e.g.
Option,Result) helps avoid creating illegal data from the source. Using ADT data require pattern match all cases, avoiding forgetting handling one case (except when using escape hatch likeunwrap()). - Rust reduces bugs caused by unwanted accidental mutation.
- Explicit
.clone()avoids accidentally copying container like in C++. - Managing dependencies is much easier in Rust than in C/C++.
- Rust's generics, traits and standard library design learned from mistakes in C++.
- ...
- Algebraic data type (e.g.
- "Memory safety can only be achieved by Rust." No. Most GC languages are memory-safe. 31 Memory safety of existing C/C++ applications can be achieved via Fil-C.
- "Manual memory management is always faster than tracing GC." No. Moving GCs 32 have better throughput in allocation and deallocation 33 34. In manual memory management, freeing a large structure may cause big lag. Using
Arcinvolves atomic operations which may become bottleneck when contended. - "The old C/C++ codebases are already battle-tested, so there is no value in rewriting them in Rust." No. If they won't ever add any new feature and don't do any large refactoring, only accepting small bug fixes, then they would indeed become more stable and safe over time. However, if they adds new feature or do large refactoring, then new memory/thread safety issues could emerge.
The yields of paying "Rust cost"
Rust has a lot of constraints and adds frictions in coding. What are the benefits after paying this cost?
One important benefit of Rust is to prevent most Heisenbugs.
The Heisenbugs are non-deterministic. When you try to debug it, it may stop triggering. Heisenbugs are often sensitive to timing and memory layout:
- Enabling logging and enabling sanitizers makes program run slower, which may make Heisenbug no longer trigger (or become much harder to trigger).
- Breakpoint debugger also changes timing when debugging, which may make Heisenbug no longer trigger.
- Some Heisenbugs only trigger in release build, not debug build. Sometimes it's due to timing. Sometimes it's caused by optimizations related to undefined behaviors.
- Some Heisenbugs only trigger in production environment. Some Heisenbugs only trigger in client's computer that developer cannot touch.
Heisenbugs are hard to debug, especially in large codebases.
Most Heisenbugs are related to memory safety, thread safety and mutation. Rust prevents most Heisenbugs compared to C/C++, so it greatly saves debugging time on Heisenbugs.
Note that there are still Heisenbugs that Rust cannot catch, including:
- Data race outside of memory (data race in disk, database, distributed system, etc.).
- Conditional deadlocks. Conditional
RefCellborrow conflict. - Unwanted async cancellations.
- Heisenbugs related to
unsafeand FFI (foreign function interface).
Also note that not all memory/thread safety bugs are Heisenbugs. Many are still easy to trigger and debug.
Footnotes
-
The native Rust ownership relation form a tree. Reference counting (
Rc,Arc) allows shared ownership. ↩ -
Note that here "reference" here means reference in general OOP context (where there is no distinction between ownership and non-owning reference, think about reference in Java/C#/JS/Python). This is different to the Rust reference. I will use "borrow" for Rust reference in this article. ↩
-
Often the borrow checker issues (including contagious borrow issue) can be workarounded by refactoring: reorganize data structure, reorganize code and abstractions. However, new requirements can easily break existing architecture, so using refactoring to tackle borrow checker issues will require frequent large refactoring. "The most fundamental issue is that the borrow checker forces a refactor at the most inconvenient times." See also. If most mutable data is put into arena in the right beginning, then it will require fewer refactoring on requirement change. ↩
-
The borrow crate creates many new types for different combinations of field borrows. One downside is that the remaining un-borrowed parts need to be manually passed. It also faces the same issue as view type: doesn't work well with encapsulation, because internal field info is leaked into type. But the borrow crate is more reliable than
RefCell: no need to worry runtime panic as long as it compiles. ↩ -
These two solutions address struct field contagious borrow. But contagious borrow can also happen to containers. To encode the information of borrowing
i-th element of aVecinto type, it requires dependent type, depending on runtime value ofi. Adding dependent type into language is much more complex. ↩ -
In old versions of ClickHouse, doing direct mutation is not performant, so developers wanting high-throughput mutation have to manually turn updates into aggregations. But modern versions of ClickHouse supports fast direct update, see also. It's also implemented using mutation-as-data idea: changes are written to "patch parts". Quering checks patch parts. Patch parts are merged into base data in background. ↩
-
Standard library has
split_offthat mutates the container. multi_mut provides a solution of split borrow ofBTreeMap. ↩ -
Exact numbers may be different. The idea is that the "performance cost contribution" of code is highly biased (fat-tail distribution). ↩
-
JetBrains IDEs semantic coloring can be configured so that captured values are in another color. This can make capturing more obvious. ↩
-
Having both ID and object reference introduces friction of translating between ID and object reference. Some ORM will malfunction if there exists two objects with the same primary key. ↩
-
Each slotmap ensures key uniqueness, but if you mix keys of different slotmaps, the different keys of different slotmap may duplicate. Using the wrong key may successfully get an element but logically wrong. id-arena avoids that by attaching arena id into key, but that makes key larger. ↩
-
The solution of putting arena into TLS then read TLS in
Debug::fmtis used by Rust compiler. Note that Rust compiler's most arenas are append-only (similar to bumpalo and append_only_vec). The interior mutability of append-only arena is safe (free ofRefCellborrow conflict). ButRefCell-based interior mutability is much more risky. For them, ifDebug::fmtborrows arena, then doing debug logging when mutably borrowing arena will causeRefCellborrow error. ↩ -
The
noaliashelps optimization but its practical effect is still limited. Also the LLVMnoaliasis an attribute to function argument and return value. It cannot be added to local variables. The actual aliasing analysis mostly depends on pointer provenance analysis. ↩ -
One may intuitively think that clone is similar to copy, so
Cell<T>should also be safe whenTjust satisfiesClone. However it's not safe when it creates self-reference then clear itself inclone. See also. ↩ -
Sometimes, having fine-grained lock is slower because of more lock/unlock operations. But sometimes having fine-grained lock is faster because it allows higher parallelism. Sometimes fine-grained lock can cause deadlock but coarse-grained lock won't deadlock. It depends on exact case. ↩
-
Some GC (e.g. ZGC) use load barrier. But that load barrier doesn't involve atomic read-modify-write operation so it's faster than cloning
Arc. ↩ -
See also. That was in 2020. Unsure whether it changed now. One possible reason is that ARM allows weaker memory order than X86. Also, Apple's languages Swift and Objective-C use reference counting almost everywhere, so possibly Apple payed more efforts in optimizing atomic reference counting in hardware. ↩
-
Tokio commonly uses
Arcinternally. In Tokio every time a sleep future or IO future is created, it callsscheduler::Handle::current()which clones anArc(and theArcdrops when future drops). ThatArc's pointee is per-runtime. So every time a sleep/IO future is created/dropped, it contends the per-Tokio-runtime atomic counter. TheArcis needed because you can run multiple instances of Tokio runtime in a Rust program and dynamically create/close Tokio runtimes. It cannot use thread local to access runtime because the future can be sent to a non-Tokio thread and be block-waited byfutures::executor::block_on, and the future has to stay memory-safe even after the Tokio runtime exits. In Golang there is no such atomic counter because one process has only one goroutine scheduler, and it won't exit until process exits. Apart from the per-runtime atomic counter, Tokio has some per-runtime mutexes that also cause contention. On contrary, in thread-per-core runtimes like monoio, the future cannot be sent across threads so it uses thread-local andRcto reference runtime data, which don't cause cache contention. That said, in most real-world web servers the per-runtime atomic counter won't be bottleneck because the real bottleneck is likely waiting on database. ↩ -
CachePaddedis from crossbeam. TheCachePaddedis actually for padding two counters inArcInner, not for padding theArc<T>. It avoids different two-layer-arcs' counters be in same cache line. ↩ -
Tracing GC is faster for short-lived programs (such as some CLI programs and serverless functions), because there's no need to free memory for individual objects on exit. Example: My JavaScript is Faster than Your Rust. The same optimization is also achievable in Rust, but require extra work (e.g.
mem::forget, bump allocator). ↩ -
It lags because it need to do many counter decrement and deallocation for each individual object. Can be workarounded by sending the
Arcto another thread and drop in that thread. Also, for deep structures, dropping may stack overflow. ↩ -
Contended atomic operations (many threads touch one atomic value at the same time) are much slower than when not contended. Its cost also include memory block allocation and freeing. ↩
-
GC frequency is roughly porpotional to allocation speed divide by free memory. In generational GC, a minor GC only scans young generation, whose cost is roughly count of living young generation objects. But it still need to occasionally do full GC. ↩
-
When running in tools like Miri, the pointer provenance will be accurately tracked at runtime. In Miri, accessing memory using a pointer with no provenance triggers error. But in LLVM optimization, it only does static analyze to code, and it cannot always analyze full pointer provenance information, especially when it involves FFI (foreign function interface). When LLVM cannot analyze provenance, related optimizations will not be applied. You don't need to care about pointer provenance issues related to FFI. ↩
-
When there is some other constraint, a byte can have less than 258 possible values in LLVM. ↩
-
Some may intuitively think
'staticis top type (likeanyin TypeScript andObjectin Java) because it's the most "general". However, in Rust, lifetime is constraint, so the most general one is no constraint, and the most specific one is the hardest constraint. The relation is inverted. In Rust narrowing lifetime is safe but expanding lifetime is not safe, similar to java converting any type toObjectis safe but convertingObjectto another type doesn't necessarily work. ↩ -
a() || b()will not executeb()ifa()returns true.a() && b()will not executeb()ifa()returns false. ↩ -
It's actually "treated as immutable". It can be actually mutable when interior mutability is involved. ↩
-
Although interior mutability has visible
Cellthings in types, the cell can be hidden in another type, then the interior mutability becomes invisible in types (Except using the unstable traitFreeze). ↩ -
A wrong
unsafecode in Rust can make memory/thread safety issue trigger in safe code. The impact ofunsafecode is not limited tounsafecode. ↩ -
Golang is not memory-safe under data race. Golang strings, fat pointers and slices has tearing issue. Golang map is not thread-safe. ↩
-
Golang GC is non-moving. Most other mainstream GC (e.g. Hotsopt JVM, CLR) are moving. ↩
-
In Rust, bump allocator can also achieve high throughput of allocation and deallocation. But using bump allocator requires extra work (contagious lifetime annotations). The conventional "malloc/free" allocators often has lower throughput than an optimized moving GC because they need to do more bookkeeping. Note that moving GC require much more free memory to achieve high throughput. Without enough free memory, moving GC will cause big lag. ↩
-
It's commonly told that moving GC has another benefit: handling memory fragmentation. When not using moving GC, fragmentation can still be alleviated by better allocation strategy (similar size-class allocate together). Fragmentation is also alleviated by virtual memory (memory fragmentation in page level don't waste physical memory). Also, RAM is cheaper now, so fragmentation cost is more affordable. Fragmentation is not a problem now (except for some rare cases). Moving GC can theoretically improve cache locality by avoiding fragmentation, but manual memory management can improve cache locality by reusing just-freed memory region. Fragmentation wastes memory but moving GC require larger free memory to achieve high thoughput. ↩